


Rozwiązujemy maturę próbną 2022 z informatyki
Tym razem coś dla młodszych czytelników bloga, chociaż pewnie nie tylko ich może to zainteresować. Zbliża się maj, a skoro maj, to matury, w tym ta z informatyki. Pomyślałem, że może Was zaciekawić, jak osoba pracująca od kilku lat w IT rozwiązałaby zadania, które pojawiły się na maturze próbnej w grudniu 2022 roku.
Uwagi wstępne
Zanim jednak przejdziemy do rozwiązywania zadań, parę uwag wstępnych ode mnie:
- Nie będę podawać treści zadań. Sam brałem je ze strony arkusze.pl (kopia na archive.org) i Ty też możesz je stamtąd wziąć.
- Nie jestem ani nauczycielem, ani egzaminatorem, stąd nie mam pojęcia, czy moje odpowiedzi wstrzelą się w klucz. Zapoznałem się z dokumentem zasad oceniania rozwiązań zadań, ale nie oznacza to, że moje rozwiązania miałyby zawsze maksimum punktów.
- Maturę z informatyki zdawałem ok. 15 lat temu, więc nie jestem na bieżąco z wymaganiami ani z tym, co jest w aktualnym programie nauczania. Starałem się jednak w tej kwestii doszkolić z różnych źródeł.
- Pominę rozwiązywanie zadań z Excela (zad. 4 EKOdom) i z baz danych (zad. 5 Hotel „Panorama”). Jest to spowodowane tylko i wyłącznie tym, że chcę skrócić ten artykuł, więc postanowiłem pominąć Excela jako najmniej programistycznego. Natomiast bazy danych pominąłem z tego powodu, że nie wymyśliłem, jak je fajnie pokazać online, a nie chcę wrzucać surowego SQL-a (a w Accessie bawić się nie będziemy).
- Przykłady napiszę w Javie (z OpenJDK 17). Jest to język, w którym nie piszę na co dzień, ale poziom zadań maturalnych nie wymaga głębokiej znajomości języka. Dopuszczalne są też Python, Pascal i C++, ale stwierdziłem, że z chęcią przypomnę sobie Javę.
- Na marginesie dodam, że sam pisałem maturę w Pascalu, ale dziś brałbym Pythona albo Javę. C++ jest trudny do debugowania i w warunkach stresu można się łatwo zgubić, natomiast Pascal jest przestarzały. Zarówno Java, jak i Python są nowoczesnymi językami z bogatą biblioteką standardową i potrafią sensownie informować o problemach w kodzie.
- Jeśli wybierzesz Javę, od razu wybierz edytor IntelliJ IDEA, bo zapewni Ci podpowiedzi nieocenione w trakcie egzaminu. Analogicznie do Pythona polecam PyCharm z tego samego powodu. Oba edytory są zarówno na Windowsie, jak i Linuksie, i (z tego, co widziałem) dopuszczone na egzaminie.
- Jeśli czyta to ktoś mocno obeznany z Javą, to celowo nie stosowałem konstrukcji „bardziej zaawansowanych”, jak np. strumienie. Nie wiem, czy w liceum ktokolwiek poznaje takie rzeczy, a też chciałem, żeby kod wyglądał jak najbardziej uniwersalnie, do prostego przełożenia na dowolny inny język.
- Wszystko w kodzie będę nazywać po angielsku, tak jak to się robi w dobrze prowadzonych aplikacjach.
Zadanie 1. Kosmiczny mecz
Z opisu zadania możemy już dojść do wstępnych założeń związanych z implementacją:
- W pliku mamy jedną linijkę, więc taki też scenariusz odczytu załóżmy.
- Mamy informację, że tekst składa się z 10000 znaków, ale w Javie czy Pythonie nie będzie nas to interesować. Będziemy po prostu odczytywać string znak po znaku (metodą
charAt(indeks)). Jedynie, co warto zrobić, to obcięcie białych znaków na przodzie i końcu, aby nie zaburzyły iteracji.
Przygotowanie do rozwiązania
Przygotujmy wstępny kod do rozwiązania zadania. Analogiczny będę używać przy dalszych zadaniach, więc później będę co najwyżej tylko opisywać różnice, a teraz bardziej szczegółowo.
Napiszmy metodę w głównej klasie aplikacji, która odczyta wskazany plik:
private static String readFile(String path) throws IOException {
Path filePath = Path.of(path);
String content = Files.readString(filePath);
return content.trim();
}
Do tego dopiszmy metodę zapisującą wyniki do pliku:
private static void writeResults(Iterable<String> results) throws IOException {
Path filePath = Path.of("./wyniki1.txt");
Files.write(filePath, results);
}
Skoro jest to Java będąca przede wszystkim językiem obiektowym, to każde zadanie niech będzie odrębną klasą. Zdefiniujmy interfejs, który spełnią wszystkie zadania, aby potem łatwo po nich iterować. Zauważmy, że każde ma zwrócić odpowiedź w postaci tekstu, więc najprościej jest zrobić tak:
interface Task {
String getTaskName();
String doTask(String entry);
}
getTaskName() będzie funkcją zwracającą numer zadania.
W main() stwórzmy pętlę, która odczyta pliki, przeiteruje po zadaniach, wypisze ich rezultaty i zapisze do pliku. Ja użyję następującego kodu:
public static void main(String[] args) throws IOException {
Task[] tasks = new Task[] { new FirstTask(), new SecondTask(), new ThirdTask() };
String sampleData = readFile("./mecz_przyklad.txt");
String realData = readFile("./mecz.txt");
ArrayList<String> results = new ArrayList<String>();
for (Task task : tasks) {
String name = task.getTaskName();
String sampleSolution = task.doTask(sampleData);
String realSolution = task.doTask(realData);
System.out.println(name);
System.out.println(sampleSolution);
System.out.println(realSolution);
results.add(String.format("%s: %s", name, realSolution));
}
writeResults(results);
}
Zadanie 1.1
W tym przypadku posłużymy się bardzo prostą pętlą porównującą dwa znaki znajdujące się obok siebie. Należy tylko pamiętać, że albo iterujemy od 1 do końca (wtedy sprawdzamy aktualny z poprzednim), albo od 0 do koniec-1 (wtedy sprawdzamy aktualny z następnym). Myślę, że kodu nie trzeba za bardzo tłumaczyć.
class FirstTask implements Task {
public String getTaskName() {
return "1.1.";
}
public String doTask(String entry) {
int result = 0;
for (int i = 1; i < entry.length(); i++) {
Character previous = entry.charAt(i - 1);
Character current = entry.charAt(i);
if (previous != current) {
result++;
}
}
return Integer.toString(result);
}
}
Kod możesz sprawdzić na Replit wraz z resztą podzadań.
Warto zwrócić uwagę, że ktoś bardziej zaawansowany mógłby się pokusić o rozwiązanie z wykorzystaniem wyrażeń regularnych, ale one się tutaj nie sprawdzą. W ich przypadku, gdy zostanie wykryta jakaś grupa znaków spełniająca wzorzec, znaki z niej nie mogą spełniać kolejnego wzorca. Dlatego w przypadku pokazanym w zadaniu (we fragmencie BABA) mamy 3 razy pożądaną sytuację, a wyrażenie regularne (np. takie: /([A-Z])(?!\1)[A-Z]/) zwróciłoby 2 (tutaj możesz to sprawdzić).
Zadanie 1.2
W przypadku tego zadania również będziemy iterować znak po znaku. W trakcie iteracji spisujemy do dwóch zmiennych, ile każda z drużyn zdobyła punktów. Co jest inne względem poprzedniego zadania to fakt, że musimy przerwać iterację w momencie, gdy jednej z drużyn naliczyliśmy 1000 punktów, a druga ma co najmniej 3 punkty mniej. Można to zrobić na dwa sposoby:
- Pętla
while, gdzie sprawdzamy w warunku: czy istnieją jeszcze znaki, oraz czy warunek przerwania (1000 punktów itd.) jest spełniony. - Pętla
forjak w poprzednim zadaniu, w której damyifsprawdzający warunek przerwania. Jeśli jest prawdziwy, przerywamy pętlę za pomocąbreakalboreturn.
Przyznam, że nie wiem, które rozwiązanie na maturze byłoby lepsze. Na pierwszym roku studiów uczono mnie, aby nie używać break, natomiast w pracy, dla lepszej czytelności kodu, poszedłbym w to drugie rozwiązanie. Założę jednak, że w liceach podchodzi się tak samo do kwestii break jak na studiach, więc użyłbym pierwszego sposobu. Aby jednak poprawić nieco czytelność, utworzę dodatkową metodę do sprawdzania warunku przerwania iteracji, którą wykorzystam ponownie do określenia, kto wygrał. W przypadku for, w warunku dałbym od razu return zwracający odpowiednie dane.
Kod napisałbym następująco:
class SecondTask implements Task {
private static final String resultFormat = "%s %d:%d";
public String getTaskName() {
return "1.2.";
}
public String doTask(String entry) {
int a = 0;
int b = 0;
int i = 0;
while (i < entry.length() && !hasWon(a, b) && !hasWon(b, a)) {
Character whoWon = entry.charAt(i);
if (whoWon == 'A') {
a++;
} else if (whoWon == 'B') {
b++;
}
i++;
}
String result = "Brak zwycięzcy";
if (hasWon(a, b)) {
result = String.format(resultFormat, "A", a, b);
} else if (hasWon(b, a)) {
result = String.format(resultFormat, "B", a, b);
}
return result;
}
private boolean hasWon(int score, int opponentScore) {
return score >= 1000 && score - opponentScore >= 3;
}
}
Kod możesz sprawdzić na Replit wraz z resztą podzadań. Zamieściłem tam też jako zakomentowaną drugą wersję z pętlą for, abyś zdecydował(a) na własną rękę, co jest czytelniejsze i co wolisz napisać.
Zadanie 1.3
W tym zadaniu mamy do zrobienia trzy rzeczy, które możemy wykonać w jednej pętli jednocześnie:
- Odliczanie, ile razy z rzędu powtórzył się aktualny znak. W kodzie, który dałem niżej,
currentRunjest licznikiem, acurrentRunCharprzechowuje aktualny znak. - Odliczanie, ile razy znak powtórzył się przynajmniej 10 razy z rzędu (dobra passa). Odliczam to w zmiennej
goodRuns. - Sprawdzenie, dla którego znaku było najwięcej powtórzeń.
Iterując znak po znaku, musimy sprawdzić, czy aktualny w iteracji jest taki sam jak aktualnie odliczany. Jeśli tak, zwiększamy licznik i od razu możemy sprawdzić dwie pozostałe rzeczy: czy jest to już dobra passa (== 10), oraz czy jest większa od aktualnie największej. W przeciwnym przypadku resetujemy licznik znaku i go zmieniamy.
class ThirdTask implements Task {
private static final int minGoodRun = 10;
public String getTaskName() {
return "1.3.";
}
public String doTask(String entry) {
int goodRuns = 0;
int currentRun = 0;
int bestRun = 0;
Character currentRunChar = ' ';
Character bestRunChar = ' ';
for (int i = 0; i < entry.length(); i++) {
Character current = entry.charAt(i);
if (currentRunChar == current) {
currentRun++;
if (currentRun == minGoodRun) {
goodRuns++;
}
if (currentRun >= minGoodRun && currentRun > bestRun) {
bestRun = currentRun;
bestRunChar = currentRunChar;
}
} else {
currentRun = 1;
currentRunChar = current;
}
}
return String.format("%d %s %d", goodRuns, bestRunChar, bestRun);
}
}
Alternatywnie, akurat tutaj możemy wykonać to zadanie wyrażeniem regularnym. /(\w)\1{9,}/ znajdzie wszystkie powtórzenia 10 znaków z rzędu. Wówczas odpowiednimi funkcjami musimy jedynie zliczyć liczbę tych wystąpień i sprawdzić, który znak jest w najdłuższym z dopasowań. Aczkolwiek nie podałem wyżej rozwiązania tego typu, bo na maturze raczej nie kombinowałbym z pisaniem wyrażeń regularnych w przypadkach, które można obsłużyć prostą iteracją. Tym bardziej, że w arkuszu odpowiedzi nie było ani słowa o użyciu wyrażeń regularnych.
Kod możesz sprawdzić na Replit wraz z resztą podzadań. W komentarzu możesz zobaczyć wersję zapisaną wyrażeniem regularnym, jeśli jesteś ciekaw(a), jak w ten sposób można rozwiązać to zadanie.
Podsumowanie
Całość kodu znajdziesz w wersji do uruchomienia na Replit. Odpowiedzi, które widzimy w konsoli, zgadzają się z odpowiedziami zarówno dla plików mecz_przyklad.txt (wyniki w treściach zadań), jak i mecz.txt (wyniki w arkuszu z odpowiedziami).
Podsumowując, zadanie 1 opierało się w całości na bardzo prostych iteracjach. Nie było potrzeby wymyślania żadnych bardziej skomplikowanych rozwiązań, a nawet mogłyby się one zupełnie nie sprawdzić (jak wyrażenie regularne w 1.1).
Zadanie 2. Strzałki
W tym zadaniu trzeba od razu zauważyć, że mamy do czynienia z drzewem binarnym. Widać to od razu na przykładzie, ale nie zawsze należy się sugerować przykładami. Na szczęście kod też to pokazuje, i to na dwa sposoby:
- Mamy wewnątrz funkcji dwa wywołania rekurencyjne, więc każde z nich będzie się „dzielić” na dwa. A drzewo binarne to drzewo, gdzie każdy węzeł ma maksymalnie dwójkę dzieci, czyli węzłów wychodzących od niego.
- Nieco mniej oczywiste, ale można zauważyć, że wzory i to nic innego jak wzory na lewe i prawe dziecko w kopcu binarnym, który jest szczególnym przypadkiem drzewa binarnego.
Zadanie 2.1
Tutaj tak naprawdę musimy po prostu rozszerzyć pokazany w treści zadania przykład do 10 węzłów. Przerysuj tamten rysunek, a następnie oblicz wzory i dla (czyli 6 i 7). Narysuj kółka (węzły) podpisane tymi liczbami pod 3 i je połącz. Powtórz to samo dla 4 i 5.
Pamiętaj tylko, że , stąd węzeł podpisany jako 10 powinien być ostatnim, który narysujesz.
Rysunek będzie wyglądać następująco:

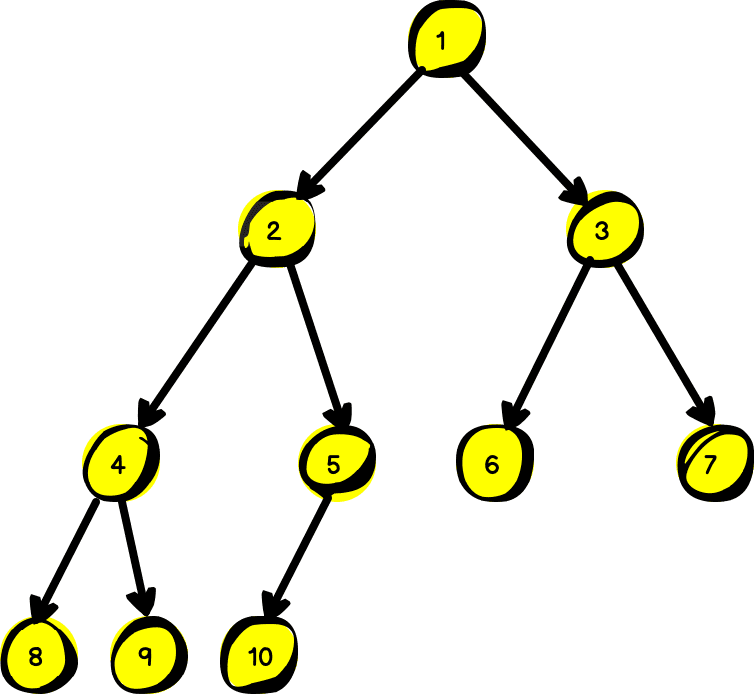
Zadanie 2.2
W przypadku drzew binarnych połączeń jest zawsze . Wzór na to możemy otrzymać, znając prostą własność drzew binarnych: każdy węzeł, poza korzeniem (węzłem, od którego zaczynamy), ma tylko jednego rodzica, czyli jest jedna strzałka prowadząca do niego. Skoro mamy węzłów, a tylko do jednego z nich (korzenia) nie prowadzi żadna strzałka, to tych strzałek musi być .
Stąd odpowiedzi:
- a) dla : 19 strzałek
- b) dla dowolnego N:
Zadanie na szczęście nie jest podchwytliwe i mamy rysuj(1), więc odliczanie zaczynamy od węzła 1, stąd nie musimy w żaden sposób modyfikować wzoru. Jednak jeśli zamiast 1 mielibyśmy inną liczbę, wówczas musielibyśmy jedynie zmniejszyć liczbę strzałek o różnicę między argumentem funkcji rysuj a 1. Na przykład, dla z rysuj(15) mielibyśmy 5 strzałek, bo .
Warto dodać, że w zadaniu nigdy nie mielibyśmy do obliczenia przypadku z rysuj(0), bo wówczas rekurencja nigdy by się nie zakończyła (, więc warunek będzie zawsze spełniony).
Zadanie 2.3
To zadanie wymaga od nas już bardziej szczegółowej wiedzy z drzew binarnych, jednak wciąż nie jest to nic niemożliwego. Możemy znać konkretny wzór albo dojść do niego, znając właściwości tego typu struktury.
Załóżmy, że na maturze nie znasz konkretnych wzorów. Jak w takim razie to obliczyć? Otóż przypadek, który tutaj mamy, jest idealnie zbalansowanym drzewem binarnym, czyli takim, gdzie węzły rozkładają się równomiernie. Gdybyśmy mieli do czynienia z drzewem przeszukiwań binarnych, oznaczałoby to, że znalezienie jakiegokolwiek elementu zajmowałoby tyle czasu, co dla idealnego przypadku według złożoności obliczeniowej tej struktury. A tym idealnym przypadkiem jest złożoność logarytmiczna.
Tylko skoro logarytm, to który? Teraz spójrz w ten sposób — drzewo jest binarne, więc wszystko dzieli się na 2. W takim razie możemy śmiało użyć logarytmu o podstawie 2. Obliczmy więc przypadek z przykładu: . Niestety, wychodzi , ale możemy to zaokrąglić. W tym przypadku zaokrąglamy w dół, bo liczba, dla której logarytm jest całkowity, zawsze jest pierwszą w wierszu. Potwierdza to przykład z zadania. Możemy też posprawdzać to na rysunku, który sami zrobiliśmy, obliczając logarytm np. dla 8, 9 i 10.
Innymi słowy wzór, którego szukamy, to (logarytm jest owinięty w „podłogę”, czyli operację zaokrąglenia w dół).
W takim razie dla nasza odpowiedź to .
Po kolejności zadań domyślam się, że można spokojnie na maturze używać kalkulatora wbudowanego w komputer. Jeśli nie, warto znaleźć całkowite wartości logarytmów dookoła, np. dla 5 są to i , stąd wiemy, że zaokrąglenie w dół będzie wynosić tyle, co ostatni logarytm, który dał nam wartość całkowitą. Żeby obliczyć to w głowie, wystarczy znać kilkanaście pierwszych potęg dwójki, co akurat jest bardzo łatwo zapamiętać, szczególnie jak się interesuje informatyką.
Jeszcze dodam na marginesie: w różnych źródłach można też znaleźć wzór niekoniecznie na to, co tutaj szukaliśmy, ale po prostu na wysokość zbalansowanego drzewa binarnego. Wzór ten to: (logarytm jest owinięty operacją „sufitu”, czyli zaokrąglenia w górę). Wówczas żeby uzyskać liczbę połączeń, musimy po prostu od wyniku tego wzoru odjąć 1, bo wysokość drzewa będzie zawsze o 1 większa od liczby połączeń, które musimy przejść z góry na dół (z analogicznego powodu, co w poprzednim zadaniu).
Zadanie 2.4
Przygotowanie do rozwiązania
W kodzie zadanie to rozpiszemy nieco prościej niż ostatnio. Mamy tu tylko jedno krótkie zadanie, więc możemy wszystko dać w jednej klasie jako metody statyczne.
Przejdźmy w takim razie do zorganizowania odczytu pliku. Tym razem nasz plik z danymi ma 1000 wierszy, a w każdym z nich dwie liczby uporządkowane rosnąco. Oznacza to, że lepiej będzie skorzystać z funkcji odczytującej plik linia po linii, a także od razu przekonwertować liczby na typ liczbowy (w Javie: int). Możemy to zrobić w następujący sposób:
private static List<int[]> readFile(String path) throws IOException {
Path filePath = Path.of(path);
List<String> content = Files.readAllLines(filePath);
List<int[]> result = new ArrayList();
for (String line : content) {
String[] pair = line.split(" ");
result.add(new int[] { Integer.parseInt(pair[0]), Integer.parseInt(pair[1]) });
}
return result;
}
Sposób zapisania pliku wynikowego możemy mieć taki sam, nie będzie tu żadnej różnicy.
Rozwiązanie
Aby rozwiązać to zadanie, wystarczy zauważyć, że wszystko, czego potrzebujemy, to przepisać funkcję rysuj(x) do naszego kodu z drobnymi modyfikacjami. Bierze się to z faktu, że jeśli zaczniemy rozpisywać drzewo od jakiejś wartości, uzyskujemy potem jedynie te wartości, do których bezpośrednio dojdziemy. Stąd, powołując się na przykład, wywołując rysuj(1), trafimy na 4, a rysuj(3) nigdy nie trafi na 5.
To, co musimy dopisać do tej funkcji, to kod sprawdzający, czy trafiliśmy na drugą liczbę. Ja podszedłem do tego następująco:
private static boolean check(int x, int y, int N) {
if (x == y) {
return true;
}
boolean left = false;
boolean right = false;
if (2 * x <= N) {
left = check(2 * x, y, N);
}
if (2 * x + 1 <= N) {
right = check(2 * x + 1, y, N);
}
return left || right;
}
Teraz po kolei, co tu się dzieje:
- Oryginalnie funkcja
rysuj(x)miała tylko jeden argument. Tutaj przekazuję aż trzy:x— pierwsza liczba z pary, od której zaczynamy poszukiwaniay— szukana liczbaN— limit wielkości drzewa. Moglibyśmy użyć stałej o wartości100000, ale chciałem mieć możliwość zweryfikowania w kodzie przykładów podanych w zadaniu, stąd przesunąłem to do zmiennej w argumencie
- Na początku sprawdzam, czy trafiliśmy na szukaną liczbę. Jeśli tak, przerywamy rekurencję i zwracamy prawdę.
- Jeśli nie, będziemy musieli sprawdzić rekurencyjnie lewe i prawe gałęzie. Z racji tego, że nie wiemy, czy w ogóle w nie wejdziemy (kwestia warunku z
N), przypiszmy do zmiennych, które przechowają wyniki rekurencji, wartość fałsz. - Dalej mamy powtórzony kod z treści zadania. Jedyne, co usunąłem, to rysowanie strzałek, bo nas tutaj zupełnie nie interesuje.
- Na koniec zwracam wyniki w postaci
left || right. Wykonuję operację||(OR, logicznelub), ponieważ interesuje nas, czy którakolwiek z gałęzi zwróciła prawdę. Tak się składa, że||zwraca fałsz jedynie wtedy, gdy po obu stronach operatora są wartości fałszywe, a w innych przypadkach prawdę, więc idealnie pasuje do naszego zastosowania.
Całość kodu znajdziesz na Replit.
Podsumowując, to zadanie sprowadziło się w dużej mierze do przepisania kodu, który został nam dostarczony wraz z zadaniem. Musieliśmy tylko go przerobić, aby zamiast rysować, sprawdzał warunek.
Zadanie 3. Liczby
Zadanie jest w całości poświęcone liczbom pierwszym, więc od razu polecam lekturę dwóch z czterech artykułów, które napisałem na ten temat:
Tutaj szczególnie przydatny będzie drugi z tych artykułów, gdzie opisałem sito Eratostenesa, któremu jest poświęcone zadanie.
Zadanie 3.1
Zaczniemy od zadania teoretycznego, czyli uzupełnienia luk w rozpisanym w zadaniu algorytmie sita Eratostenesa.
Po kolei będą to, według karty odpowiedzi (wraz z wytłumaczeniem):
N- W algorytmie pierwszy raz iterujemy po wszystkich liczbach, aby nadać początkowe wartości w tablicy. Za drugim razem również musimy przejść po wszystkich.
- Aczkolwiek tutaj może być wpisane też , co zaraz wytłumaczę.
PRAWDA- Wartość
PRAWDAoznacza, że liczba jest pierwsza. Sito Eratostenesa polega na tym, że zawsze gdy trafimy na liczbę pierwszą, musimy następnie wykonać iterację po jej wielokrotnościach.
- Wartość
i*i- Pierwszą wartością, którą oznaczymy jako liczbę złożoną (
FAŁSZ), jest aktualna liczba podniesiona do kwadratu. - Teraz, jeśli czytałeś(-aś) mój artykuł o znajdowaniu liczb pierwszych, możesz mieć zgrzyt, bo napisałem tam, żeby iterować po wielokrotnościach
i. Prawda jest jednak taka, że możemy zacząć od kwadratu tej liczby, ponieważ wszystkie mniejsze wielokrotności są już oznaczone jako liczby złożone.- Przykładowo, dla liczby 7:
7*2jest oznaczone przez 2,7*3przez 3,7*4przez 2,7*5przez 5,7*6przez 2. Dopiero7*7jest liczbą, której żadna dotychczasowa iteracja nie dotknęła.
- Przykładowo, dla liczby 7:
- W tym momencie, skoro na karcie odpowiedzi jest
i*i, to stosując tę optymalizację, możemy zarazem, jak wspomniałem na początku, zmniejszyć liczbę iteracji zNdo . Nawet jest to wskazane w implementacjach, żeby nie przekroczyć zakresu typu liczbowego.
- Pierwszą wartością, którą oznaczymy jako liczbę złożoną (
FAŁSZ- Każde wystąpienie w pętli to liczba złożona, więc oznaczamy je fałszem.
j+i- Licznik pętli inkrementujemy o
i, bo to jej wielokrotności nas interesują.
- Licznik pętli inkrementujemy o
A dlaczego piszę, że według karty odpowiedzi? Dlaczego nie podałem odpowiedzi, jakie ja bym napisał?
Inne możliwe odpowiedzi?
Przyznam, że czytając kartę odpowiedzi do tego zadania, mam mały zgrzyt. Mianowicie, przeglądając różne źródła, mamy dwie opcje napisania tego algorytmu:
- Bez optymalizacji — wtedy iterujemy do
N, a początkową wartościąjbędziei+i. - Z optymalizacją — wówczas iterujemy do , a początkową wartością
jbędziei*i.
Karta odpowiedzi daje nam mieszankę tych dwóch podejść. Prawidłowe, ale na swój sposób dziwne i niemające sensu, bo zmusza niepotrzebnie do podnoszenia do kwadratu dużych liczb, co dość szybko skończy się przekroczeniem zakresu zmiennej całkowitoliczbowej. Jeśli język o tym poinformuje, to miło, ale większość po prostu przekręci licznik. Implementując algorytm na maturze, możemy tego nie zauważyć.
Pamiętaj jednak, że karta odpowiedzi mówi wprost: Przykładowe poprawne rozwiązanie. Dlatego podejrzewam, że jeśli rozwiążesz na te dwa sposoby, o których wspomniałem, zamiast na dokładnie taki jak jest w karcie, również powinieneś/powinnaś mieć zaliczone to zadanie.
Przygotowanie do rozwiązania
Tym razem możemy użyć schematu projektu z zadania 1., bo tutaj również mamy do czynienia z wieloma podzadaniami. Jedynie nieco zmodyfikujemy sposób odczytu pliku, na wzór zadania 2., żeby od razu otrzymać liczby (int) zamiast całego pliku jako String:
private static List<Integer> readFile(String path) throws IOException {
Path filePath = Path.of(path);
List<String> content = Files.readAllLines(filePath);
List<Integer> result = new ArrayList();
for (String line : content) {
result.add(Integer.parseInt(line));
}
return result;
}
Oznacza to, że również nieco zmodyfikujemy interfejs zadań, który teraz będzie przyjmować listę liczb. Załóżmy także, że może zwrócić listę stringów, bo nasze odpowiedzi będą wielolinijkowe:
interface Task {
String getTaskName();
List<String> doTask(List<Integer> entries);
}
Warto zauważyć, że dwa z podzadań będą wykorzystywać sito Eratostenesa. Skorzystajmy z tego, że Java pozwala zdefiniować w interfejsie metody statyczne, i tak też zróbmy implementację tego algorytmu:
public static boolean[] getPrimeNumbers(int N) {
boolean[] sieve = new boolean[N + 1];
sieve[0] = false;
sieve[1] = false;
for (int i = 2; i <= N; i++) {
sieve[i] = true;
}
for (int i = 2; i <= Math.sqrt(N); i++) {
if (sieve[i]) {
int j = i * i;
while (j <= N) {
sieve[j] = false;
j += i;
}
}
}
return sieve;
}
Tak jak opisałem to wcześniej, zastosowałem tutaj iterację do zamiast do . Dzięki temu unikam przekroczenia zakresu int (w Javie: ), co stałoby się już przy liczbie pierwszej 146543:
Tym samym część liczb pierwszych zostałaby oznaczona jako złożone. Wyłapiemy, że coś jest nie tak, bo dostaniemy błąd, że chcemy się odwołać do ujemnych indeksów tablicy, ale wówczas pierwszą myślą w stresującym środowisku będzie dodanie warunku, żeby iterować tylko przy dodatnich j. Niestety, przy przekręceniu licznika będą też błędne, dodatnie wartości, więc to nie pomoże. Alternatywnie moglibyśmy się posiłkować przez zamianę int na long, jeśli chcielibyśmy trzymać się implementacji według karty odpowiedzi.
Zadanie 3.2
To zadanie to użycie wprost sita Eratostenesa. Po prostu przeiterujmy po kolei po liczbach i sprawdzajmy, czy pomniejszone o 1 są liczbami pierwszymi.
class FirstTask implements Task {
public String getTaskName() {
return "3.2.";
}
public List<String> doTask(List<Integer> entries) {
int result = 0;
boolean[] sieve = Task.getPrimeNumbers(1000000);
for (int number : entries) {
if (sieve[number - 1]) {
result++;
}
}
return Arrays.asList(Integer.toString(result));
}
}
Kod możesz sprawdzić na Replit wraz z resztą podzadań.
Zadanie 3.3
W tym miejscu zastosujemy sprawdzanie za pomocą prostej iteracji. Nie będziemy stosować żadnych specjalistycznych algorytmów do tego celu.
Z racji tego, że zadanie jest nieco bardziej skomplikowane, prościej było mi opisać działanie przez zamieszczenie komentarzy w kodzie:
class SecondTask implements Task {
private static final String resultFormat = "%d %d";
public String getTaskName() {
return "3.3.";
}
public List<String> doTask(List<Integer> entries) {
// na początek wykonujemy sito Eratostenesa
boolean[] sieve = Task.getPrimeNumbers(1000000);
// zmienne do przechowania wyników
int maxResult = 0;
int maxResultNumber = 0;
int minResult = 1000000;
int minResultNumber = 0;
// iterujemy po wszystkich liczbach z zadania
for (int entry : entries) {
// interesują nas tylko parzyste
// w przypadku nieparzystych przechodzimy do kolejnej
if (entry % 2 != 0) {
continue;
}
// zmienna przechowująca, ile liczba zawiera rozkładów
int result = 0;
// iterujemy po wszystkich liczbach od 2 do połowy aktualnej liczby
// od połowy wzwyż będą powtarzać się pary
for (int i = 2; i <= entry / 2; i++) {
// jeśli aktualna liczba nie jest pierwsza, przechodzimy dalej
if (!sieve[i]) {
continue;
}
// drugi składnik sumy będzie różnicą dwóch znanych nam liczb
int second = entry - i;
// jeśli drugi składnik jest liczbą pierwszą,
// inkrementujemy liczbę rozkładów
if (sieve[second]) {
result++;
}
}
// jeśli mamy jakiekolwiek rozkłady,
// sprawdźmy, czy możemy je przechować
if (result > 0) {
// sprawdzamy, czy mamy najwięcej rozkładów
if (result > maxResult) {
maxResult = result;
maxResultNumber = entry;
}
// sprawdzamy, czy mamy najmniej rozkładów
if (result < minResult) {
minResult = result;
minResultNumber = entry;
}
}
}
return Arrays.asList(String.format(resultFormat, maxResultNumber, maxResult),
String.format(resultFormat, minResultNumber, minResult));
}
}
Kod możesz sprawdzić na Replit wraz z resztą podzadań.
A jeśli interesuje Cię, jak można by to zadanie rozwiązać bardziej specjalistycznym algorytmem, możesz sprawdzić np. ten artykuł naukowy: doi:10.13140/RG.2.2.21545.01125. Podejście tam opisane wykorzystuje chińskie twierdzenie o resztach, więc może się wydawać nieco trudniejsze niż to, co pokazałem w powyższym kodzie. Na pewno nie jest to coś, o czym by się pamiętało w trakcie egzaminu.
Zadanie 3.4
Tutaj moglibyśmy napisać od zera algorytm zamieniający liczbę na szesnastkową, ale zupełnie nie ma potrzeby tego robić. Sporo języków programowania ma do tego funkcje w swojej bibliotece standardowej i Java nie jest wyjątkiem. Użyjemy wprost funkcji Integer.toHexString(liczba). Następnie przeiterujemy po wszystkich cyfrach liczby (analogicznie jak w zadaniu 1) i zliczymy wystąpienia. Użyjemy w tym celu struktury danych HashMap, którą wcześniej uzupełniliśmy o wszystkie cyfry systemu szesnastkowego.
Implementacja będzie wyglądać następująco:
import java.util.*;
class ThirdTask implements Task {
public String getTaskName() {
return "3.4.";
}
public List<String> doTask(List<Integer> entries) {
List<Character> digits = Arrays.asList('0', '1', '2', '3',
'4', '5', '6', '7',
'8', '9', 'A', 'B',
'C', 'D', 'E', 'F');
HashMap<Character, Integer> counter = new HashMap();
// uzupełnienie mapy wartościami
for (Character digit : digits) {
counter.put(digit, 0);
}
// algorytm wykonujący zadanie
for (int number : entries) {
String hex = Integer.toHexString(number).toUpperCase();
for (int i = 0; i < hex.length(); i++) {
Character current = hex.charAt(i);
counter.put(current, counter.get(current) + 1);
}
}
List<String> result = new ArrayList();
// spisanie rezultatów
for (Character digit : digits) {
result.add(String.format("%s:%d", digit, counter.get(digit)));
}
return result;
}
}
Kod możesz sprawdzić na Replit wraz z resztą podzadań.
Jeśli wybrałbyś/wybrałabyś inny język, to sytuacja z gotowymi funkcjami wygląda w nich następująco:
- Python ma wbudowaną funkcję
hex(liczba). Warto jednak zaznaczyć, że liczba będzie mieć zawsze prefiks0x, którego nie możemy brać pod uwagę przy zliczaniu cyfr do odpowiedzi. Więcej tutaj: https://docs.python.org/3/library/functions.html#hex. - Pascal zawiera funkcję
IntToHex(liczba)w modulesysutils. Więcej tutaj: https://www.freepascal.org/docs-html/rtl/sysutils/inttohex.html - C++ w swojej bibliotece standardowej zawiera funkcję
std::hex. Należy jednak pamiętać, że funkcja ta operuje na strumieniach, więc jej wynik musimy przypisać dostd::ostringstream, aby móc dalej manipulować na liczbie jako stringu. Więcej tutaj: https://en.cppreference.com/w/cpp/io/manip/hex. Poniżej natomiast przykład, w jaki sposób użyćstd::hexzstd::ostringstream:
#include <iostream>
#include <sstream>
int main() {
std::ostringstream number;
number << std::hex << 42;
// możemy otrzymać stringa, wywołując number.str()
std::cout << number.str() << "\n"; // "2a"
}
Podsumowanie
Całość kodu znajdziesz w wersji do uruchomienia na Replit. Odpowiedzi widoczne w konsoli zgadzają się dla plików liczby_przyklad.txt (wyniki w treściach zadań) i liczby.txt (wyniki w arkuszu z odpowiedziami).
Podsumowując, w tym przypadku również dostaliśmy gotowy kod, którego musieliśmy użyć w zadaniu. W zasadzie rozwiązał nam zadanie 3.2 i stanowił podstawę do 3.3. W przypadku 3.3 faktycznie trzeba było się nieco zastanowić, jak to dobrze ugryźć, ale koniec końców nie wymagało to skomplikowanej algorytmiki. Natomiast 3.4 było już zadaniem dość odrębnym od reszty.
Zadania teoretyczne
Po pominięciu zadań z Excela i baz danych bardzo płynnie przechodzimy do trzech ostatnich zadań czysto teoretycznych. Oprócz samych odpowiedzi dam też krótkie wyjaśnienie, dlaczego jest tak, a także jakie mogłyby być alternatywne odpowiedzi.
Zadanie 6. Protokoły
- Protokół wysyłania poczty elektronicznej: SMTP.
- Tutaj jedyna uwaga ode mnie jest taka, żeby się pilnować i nie pomylić wysyłania z odbieraniem. W kontekście poczty elektronicznej podczas nauki zawsze jest mowa o trzech protokołach: POP3, IMAP i SMTP, z czego tylko ten ostatni służy wysyłaniu. Wysyłać (i odbierać) pocztę można też protokołem MAPI*, ale wątpię, że trafiłby się na maturze.
- Protokół przesyłania plików: FTP.
- FTP łatwo zapamiętać, bo nawet jego pełna nazwa oznacza dosłownie „protokół transferu plików” (ang. File Transfer Protocol).
- Tutaj mogłyby się ewentualnie pojawić alternatywy: FTPS, SFTP lub TFTP, ale jak widać, każda z tych nazw zawiera cząstkę FTP.
- Szyfrowany protokół przesyłania dokumentów hipertekstowych: HTTPS.
- W przypadku nieszyfrowanego odpowiedzią byłoby oczywiście HTTP.
- Protokół odbierania poczty elektronicznej: IMAP.
- Jak wspomniałem wcześniej, alternatywnie mógłby się tu pojawić POP3.
* Na marginesie dodam, że MAPI nie jest protokołem, tylko API do komunikacji z serwerem mailowym. Bazuje na nim dopiero protokół MAPI/RPC, ale jest on powszechnie znany jako protokół MAPI, stąd to uproszczenie.
Zadanie 7
- Prawda
- Samo słowo symetryczny powinno nas nakierować, że działa w obie strony. Popularnymi algorytmami szyfrowania, gdzie mamy jeden klucz do szyfrowania i odszyfrowania, są DES (już niestosowany) i AES.
- Fałsz
- W szyfrowaniu symetrycznym mamy jeden klucz symetryczny, więc nie istnieje podział. Przedstawiony tu podział występuje w algorytmach asymetrycznych, takich jak RSA. W jego przypadku klucz prywatny służy do odszyfrowania danych, a klucz publiczny do ich zaszyfrowania.
Zadanie 8. Systemy liczbowe
Aby obliczyć działanie zapisane w systemie czwórkowym, najprościej jest po prostu zrobić to pod kreską. Należy jedynie pamiętać, że największa cyfra, którą możemy mieć, to nie 9 (jak w systemie dziesiętnym), tylko 3. Moje przykładowe obliczenie znajdziesz poniżej. Jeśli potrzebujesz wyjaśnień, to sposób obliczania w systemie dwójkowym zaprezentowałem w artykule 1 0 0 0? 0 1 0 1! 1 0 0 1 — czyli matematyka zero-jedynkowa — w tym przypadku zamiast 0 i 1 dostępnymi dla Ciebie cyframi są 0, 1, 2 i 3.

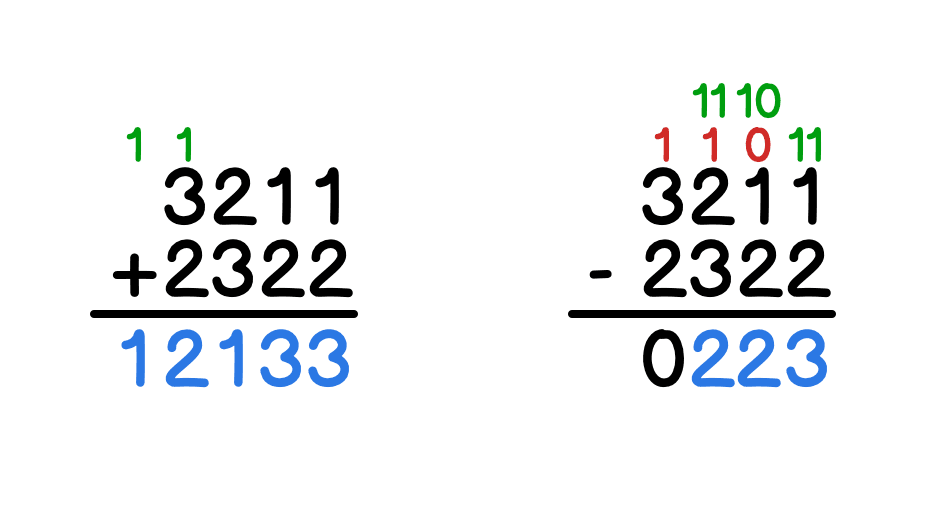
Czyli w systemie czwórkowym zapisujemy odpowiedzi: 12133 oraz 223.
W kwestii konwersji z systemu czwórkowego na szesnastkowy nie zaproponuję nic odkrywczego. Zrobiłbym to, po prostu zamieniając liczbę najpierw na system dziesiętny, a potem z dziesiętnego na szesnastkowy (algorytmy na to również pokazałem w zalinkowanym wyżej artykule). Obliczmy to najpierw dla liczby , która będzie trudniejsza:
W takim razie . Dla przypomnienia — system szesnastkowy zawiera dodatkowe cyfry A, B, C, D, E, F, które odpowiadają w systemie dziesiętnym liczbom od 10 do 15.
Powtórzmy to samo dla :
Czyli .
Słowo na koniec
Tak oto doszliśmy do końca zadań z próbnej matury z informatyki z 2022 roku. Z racji tego, że pominąłem całe dwa zadania, to straciłem 18 punktów, czyli zdobyłbym niestety tylko 64%. Może jednak wrócę jeszcze do zadań z Excela i bazodanowego, żeby nadrobić tę drobną stratę.
Na sam koniec mam małą prośbę. Jeśli widzisz jakiś błąd lub zrobiłem coś niezgodnie z kluczem, daj mi znać na moich social mediach (linki na górze, pod logiem strony) albo przez e-maila (link w stopce). Dzięki!
Zdjęcie na okładce wygenerowane przez DALL-E.


Koniecznie polub świstak.codes na Facebooku, obserwuj na Instagramie, LinkedIn lub zasubskrybuj mój kanał RSS!
Możesz też wesprzeć moją działalność klikając link poniżej:
