


Sumy kontrolne
W informatyce dużo mówimy o przechowywaniu danych i manipulacji nimi. Gdy wejdziemy w obszar teleinformatyki, poruszane są też tematy przesyłania danych. Jednak skąd wiadomo, czy dane są prawidłowe? Skąd wiemy, czy w trakcie przesyłania przez Internet plik dotarł do nas w całości? Do tego co to ma wspólnego z weryfikacją numerów kont bankowych, kart kredytowych czy PESEL-u? Zapoznajmy się z tematem sum kontrolnych i jakie mają zastosowania.
Teoria
Zacznijmy tradycyjnie od teorii, czym w ogóle jest suma kontrolna (z ang. checksum). Jest to mały blok danych dołączony do innego bloku danych, obliczony na jego podstawie, wykorzystany w celu wykrycia błędów. Warto podkreślić, że sumy kontrolne służą sprawdzeniu spójności danych, a nie weryfikacji ich poprawności czy też autentyczności.
Dla zrozumienia — spójność (integralność) danych mówi o tym, czy otrzymaliśmy dane kompletne, np. nie zostały w trakcie transmisji zniekształcone w sposób losowy. Nie ma tu mowy (najczęściej) o celowych zniekształceniach, podmianie wiadomości bądź nieprawdziwości danych.
W zależności od celu, w jakim powstał algorytm, sumy kontrolne mogą mieć różne własności. Mogą być bardzo proste i szybkie do obliczenia, ale podatne na celowe zniekształcenia. Z drugiej strony funkcje mogą być na tyle rozbudowane, że niemożliwe jest zniekształcić dane tak, aby suma kontrolna wyszła taka sama. Również niektóre sumy kontrolne mogą być także kodami korekcyjnymi (po ang. error correction code, ECC), czyli po sprawdzeniu jesteśmy w stanie określić, gdzie jest błąd, i go naprawić.
Wprowadzę też dodatkowo jeszcze jeden termin, który warto znać: kolizja. Kolizja to przypadek, kiedy dwa różne zestawy danych mają tę samą sumę kontrolną. Czy na to zezwalamy, jak często i w jakich przypadkach zależy od stopnia zaawansowania algorytmu. Najprostsze ochronią przed kolizjami, gdzie dane różnią się nieznacznie (np. numer tylko jedną cyfrą), ale nie będą w stanie wykryć wielu zmian. Natomiast te najbardziej zaawansowane, stosowane w kryptografii, powinny być odporne na kolizję w jak największym stopniu.
Cyfry kontrolne
Pierwszy przypadek sum kontrolnych, o których chciałem opowiedzieć w artykule, to cyfry kontrolne. Są one ciekawe, bo algorytmy są na tyle proste, że do ich obliczenia nie potrzebujemy nawet komputera. Często wykorzystuje się je poza światem cyfrowym we wszelkich numerach identyfikacyjnych, gdzie mimo wszystko chcemy mieć możliwość sprawdzenia poprawności. Są to przykładowo: numery kont bankowych (IBAN), kart kredytowych, PESEL, NIP, REGON, ISBN, amerykańskie SSN i wiele innych. Nie będziemy wchodzić w szczegóły, czym są konkretne składowe danych numerów w celu ich głębszej weryfikacji, tylko skupimy się na cyfrach kontrolnych. Zwróć uwagę na to, jak wszystkie te cyfry oblicza się w podobny sposób.
Pokażę tutaj różne algorytmy do sprawdzania poprawności cyfr kontrolnych w takich numerach, ale nie po to, aby wymienić ich jak najwięcej, tylko aby pokazać różnorodność podejść. Mamy jeszcze inne numery, ale zasada obliczania jest bardzo podobna, więc nie ma sensu się powielać, a szczegóły możesz zawsze doczytać w wielu źródłach w Internecie.
PESEL
Zacznijmy od numeru, który ma nadany każdy obywatel Polski, czyli PESEL. Ostatnia w nim cyfra to cyfra kontrolna. W celu sprawdzenia poprawności PESEL-u wykonujemy następujące operacje na poprzedzających go cyfrach:
- Przydzielamy kolejnym cyfrom numeru wagi: 1, 3, 7, 9, 1, 3, 7, 9, 1, 3.
- Każdą cyfrę mnożymy przez przypisaną jej wagę. Jeśli wynik wyjdzie dwucyfrowy, zapamiętujemy tylko ostatnią cyfrę.
- Sumujemy uzyskane iloczyny. Ponownie, jeśli suma wyjdzie dwuczęściowa, zapamiętujemy tylko ostatnią cyfrę.
- Uzyskany wynik odejmujemy od 10. Jest to cyfra kontrolna.
- W szczególnym przypadku, gdy mamy , zapamiętujemy tylko ostatnią cyfrę, czyli .
W kodzie (JavaScript) moglibyśmy zapisać to przykładowo w następujący sposób:
// funkcja sprawdzająca poprawność numeru PESEL
// zakładamy, że PESEL jest ciągiem znaków
function isValidPESEL(pesel) {
// tablica z wagami poszczególnych cyfr
const weights = [1, 3, 7, 9, 1, 3, 7, 9, 1, 3];
// rozbijamy PESEL na pojedyncze cyfry
// i dokonujemy ich konwersji na typ liczbowy
const digits = pesel.split('').map(x => parseInt(x));
// zmienna przechowująca sumę iloczynów cyfry i wagi
let sum = 0;
// pętla wykonująca mnożenia cyfr przez wagi,
// aby łatwo pominąć ostatnią cyfrę, iterować będziemy po tablicy wag
for (let i = 0; i < weights.length; i++) {
// do sumy dodajemy iloczyn wagi i cyfry modulo 10
// modulo 10 wydobywa ostatnią cyfrę dwucyfrowej liczby
sum += weights[i] * digits[i] % 10;
}
// obliczamy cyfrę kontrolną
const checksum = (10 - sum % 10) % 10;
// zwracamy, czy obliczona cyfra kontrolna jest taka sama
// jak ostatnia cyfra numeru PESEL
return checksum === digits.at(-1);
}
Możesz go przetestować na repl.it.
NIP
Kolejnym powszechnym w Polsce numerem jest numer identyfikacji podatkowej, czyli NIP. Tutaj sprawa wygląda podobnie, a nawet prościej, bo nie musimy przejmować się, aby zawsze brać tylko ostatnią cyfrę. Interesuje nas to dopiero na samym końcu. Algorytm jest następujący:
- Przydzielamy kolejnym cyfrom numeru wagi: 6, 5, 7, 2, 3, 4, 5, 6, 7.
- Mnożymy każdą cyfrę przez przydzieloną jej wagę i sumujemy iloczyny.
- Cyfrę kontrolną obliczamy jako resztę z dzielenia powyższej sumy przez 11 (modulo 11).
Warto zwrócić uwagę, że operacja modulo 11 może zwrócić wynik 10. W tym przypadku jednak nie bierzemy ostatniej cyfry (jak w przypadku PESEL), ponieważ numery dające taki wynik nie są nadawane.
W kodzie (JavaScript) moglibyśmy powyższy algorytm zapisać w następujący sposób:
// funkcja sprawdzająca poprawność NIP
// zakładamy, że NIP jest ciągiem znaków
function isValidNIP(nip) {
// tablica z wagami poszczególnych cyfr
const weights = [6, 5, 7, 2, 3, 4, 5, 6, 7];
// rozbijamy NIP na pojedyncze cyfry
// i dokonujemy ich konwersji na typ liczbowy
const digits = nip.split('').map(x => parseInt(x));
// zmienna przechowująca sumę iloczynów cyfry i wagi
let sum = 0;
// pętla wykonująca mnożenia cyfr przez wagi,
// aby łatwo pominąć ostatnią cyfrę, iterować będziemy po tablicy wag
for (let i = 0; i < weights.length; i++) {
// do sumy dodajemy iloczyn wagi i cyfry
sum += weights[i] * digits[i];
}
// obliczamy cyfrę kontrolną
const checksum = sum % 11;
// zwracamy, czy obliczona cyfra kontrolna jest taka sama
// jak ostatnia cyfra NIP
return checksum === digits.at(-1);
}
Możesz go przetestować na repl.it.
Dlaczego modulo 11?
Ciekawą kwestią jest użycie reszty z dzielenia przez 11 zamiast 10. Jeśli interesuje nas pojedyncza cyfra, 10 wydaje się naturalnym wyborem, bo modulo daje zakres wyników od 0 do 9. O co tu chodzi?
Niestety nie znalazłem konkretnego wyjaśnienia dla NIP-u, ale podobną sytuację mamy w ISBN-10, który jako międzynarodowy standard zawiera dużo więcej opisujących go źródeł, a rzecz wygląda tu analogicznie. Mianowicie, jeśli zmienilibyśmy cyfrę z parzystą wagą o 5 (np. z 7 na 2), zmiana nie zostałaby wykryta przez modulo 10. Analogicznie zadzieje się, jeśli zmienimy którąkolwiek cyfrę z wagą 5 o 2 lub inną parzystą wartość (np. z 2 na 4 — różnica 2, z 3 na 7 — różnica 4) — wynika to z przemienności mnożenia.
Dlaczego więc 11? Jest to liczba pierwsza i liczenie reszty jest odporne na takie przypadki. Możesz zobaczyć na tym repl.it, że dla NIP-u (bez cyfry kontrolnej) 123456321 i 123456371 (zmiana przedostatniej cyfry) dostalibyśmy taką samą cyfrę kontrolną przy modulo 10 (8), natomiast przy modulo 11 różne cyfry (8 i 5).
Warto tutaj podkreślić dwie rzeczy:
- Sytuacja ta zachodzi tylko przy cyfrach z parzystymi wagami lub wagą 5, dlatego problem ten nie występuje w PESEL-u.
- Działa to tylko wtedy, gdy przekłamana zostaje jedna cyfra.
Dlaczego akurat liczba pierwsza ma tu znaczenie? Dlatego, że 10 jest podzielne przez 2 i 5. Każda liczba parzysta jest podzielna przez 2 i gdy drugą cyfrę zmieniamy na taką, że różni się od siebie o 5, to modulo 10 wychodzi takie samo. Analogicznie jest w drugą stronę dzięki przemienności mnożenia. Zobacz przykłady:
Jeśli chcesz poznać kryjący się za tym fachowy matematyczny termin, to chodzi tu o liczby względnie pierwsze. Wagi cyfr oraz liczba, przez którą wykonujemy modulo, muszą być względnie pierwsze, aby nie występowały kolizje tego typu. W przypadku PESEL-u 10 jest względnie pierwsze do każdej z wag, w NIP-ie już nie.
Poza 11 inny przykład liczby pierwszej wykorzystywanej w obliczaniu sum kontrolnych to 97. Jest używana do obliczania sumy kontrolnej IBAN (numer konta bankowego), przy czym warto zwrócić uwagę, że tam suma kontrolna jest dwucyfrowa. 97 jest wówczas naturalnym wyborem, bo jest to największa dwucyfrowa liczba pierwsza.
ISBN-13
ISBN to standard identyfikacji książek, którego znajdziemy dwie wersje. Wspomniałem przed chwilą o ISBN-10, jednak jest to stary standard. Od 2007 r. stosuje się 13-cyfrowy ISBN-13. Sposób obliczania niewiele się różni od powyżej opisanych, ale stwierdziłem, że go opiszę, ponieważ jest prosty, a także możemy inaczej weryfikować poprawność, niż porównując ostatnią cyfrę z obliczoną przez nas. Ponadto dokładnie ten sam algorytm obliczania i sprawdzania cyfry kontrolnej jest używany też w innych numerach, np. w EAN-13.
Algorytm obliczania sumy kontrolnej jest następujący:
- Przydzielamy cyfrom na nieparzystych pozycjach wagę 1, cyfrom na parzystych 3, czyli 1, 3, 1, 3, 1, 3 itd.
- Mnożymy każdą cyfrę przez przydzieloną jej wagę i sumujemy iloczyny.
- Obliczamy resztę z dzielenia sumy przez 10 i odejmujemy od 10.
- Jeśli wynik powyższego działania jest mniejszy od 10, jest to nasza suma kontrolna. Jeśli jest równy 10, cyfra kontrolna wynosi 0.
Natomiast jak możemy sprawdzić poprawność numeru bez ręcznego obliczania cyfry? Wykonując dwa pierwsze kroki powyższego algorytmu, przy czym bierzemy też pod uwagę cyfrę kontrolną (będzie mieć wagę 1). Następnie sprawdzamy, czy wynik jest podzielny przez 10. Jeśli tak, numer jest poprawny.
Poniżej możesz zobaczyć przykładowy kod (JavaScript) obliczający cyfrę kontrolną numeru ISBN, a także kod weryfikujący ją:
// funkcja generująca sumę kontrolną dla ISBN
// zakładamy, że numer jest stringiem i podany bez myślników
function generateISBNChecksum(isbn) {
// rozbijamy ISBN na pojedyncze cyfry
// i dokonujemy ich konwersji na typ liczbowy
const digits = isbn.split('').map(x => parseInt(x));
// zmienna przechowująca sumę iloczynów cyfry i wag
let sum = 0;
// pętla wykonująca mnożenia cyfr przez wagi
for (let i = 0; i < digits.length; i++) {
// decydujemy, jaką wagę ma cyfra w zależności od jej pozycji
const weight = (i + 1) % 2 === 0 ? 3 : 1;
// do sumy dodajemy iloczyn wagi i cyfry
sum += weight * digits[i];
}
// zwracamy cyfrę kontrolną
return (10 - sum % 10) % 10;
}
// funkcja sprawdzająca sumę kontrolną dla ISBN
// zakładamy, że numer jest stringiem i podany bez myślników
function isValidISBN(isbn) {
// rozbijamy ISBN na pojedyncze cyfry
// i dokonujemy ich konwersji na typ liczbowy
const digits = isbn.split('').map(x => parseInt(x));
// zmienna przechowująca sumę iloczynów cyfry i wag
let sum = 0;
// pętla wykonująca mnożenia cyfr przez wagi
for (let i = 0; i < digits.length; i++) {
// decydujemy, jaką wagę ma cyfra w zależności od jej pozycji
const weight = (i + 1) % 2 === 0 ? 3 : 1;
// do sumy dodajemy iloczyn wagi i cyfry
sum += weight * digits[i];
}
// zwracamy, czy obliczona suma jest podzielna przez 10
return sum % 10 === 0;
}
Możesz go przetestować na repl.it.
Algorytm Luhna
W tym momencie warto zadać pytanie — czy jest jakieś uniwersalne podejście do obliczania i sprawdzania cyfr kontrolnych? Otóż tak, są takie. Najbardziej znanym i popularnym jest algorytm Luhna, znany też jako algorytm modulo 10. Jest częścią standardu ISO/IEC 7812-1 i wykorzystuje się go m.in. w numerach kart kredytowych, IMEI czy odpowiednikach PESEL w innych krajach na świecie.
Algorytm do obliczenia cyfry kontrolnej wygląda następująco:
- Odwróć numer, aby odczytywać go od prawej do lewej.
- Zsumuj cyfry na parzystych pozycjach (pozycje numerujemy od 1), tj. drugą, czwartą, szóstą itd.
- Dla cyfr na nieparzystych pozycjach:
- Pomnóż cyfrę przez 2.
- Jeśli wynik jest dwucyfrowy, dodaj do siebie jego cyfry (np. dla 18 będzie to ).
- Dodaj wynik do sumy uzyskanej w punkcie 2.
- Obliczamy resztę z dzielenia sumy przez 10 i odejmujemy od 10.
- Jeśli wynik powyższego działania jest mniejszy od 10, jest to nasza suma kontrolna. Jeśli jest równy 10, cyfra kontrolna wynosi 0.
Natomiast aby zweryfikować poprawność sumy kontrolnej, algorytm przerabiamy w następujący sposób:
- Odwróć numer, aby odczytywać go od prawej do lewej.
- Zsumuj cyfry na nieparzystych pozycjach, tj. pierwszą, trzecią, piątą itd.
- Dla cyfr na nieparzystych pozycjach wykonaj analogiczne akcje co dla parzystych w poprzednim algorytmie.
- Jeśli suma jest podzielna przez 10, numer jest poprawny.
Podejście do sumowania cyfr w wynikach dwucyfrowych
Najmniej przyjemnym do zaprogramowania elementem algorytmu Luhna jest część, gdzie mnożymy cyfry przez 2. Możemy to zaprogramować, ale wtedy będzie niepotrzebnie skomplikowane obliczeniowo. Istnieją jednak dwa sposoby, dzięki którym możemy uniknąć rozbijania liczby na dwie cyfry. Sam(a) wybierz, który bardziej do Ciebie przemawia.
Pierwszy sposób polega na tym, że jeśli wynik mnożenia jest większy od 9, należy odjąć od niego 9. Aby pokazać, że to działa, zobacz wszystkie możliwości, jakie mamy:
Natomiast jeśli chcesz uniknąć stosowania warunków, możesz podejść do rozwiązania jeszcze inaczej. Zadeklaruj tablicę [0, 2, 4, 6, 8, 1, 3, 5, 7, 9]. Następnie zamiast mnożyć przez 2, odczytaj wartość z tablicy mającej indeks równy cyfrze, którą aktualnie obsługujesz. Przykładowo, zamiast wykonać , odczytaj 6. element z tablicy (indeksowanej od zera), czyli 3. Jak możesz zauważyć, pierwsze 5 wartości w tablicy to po prostu kolejne wielokrotności 2, natomiast dalej są wielokrotności minus 9, czyli dokładnie to, co wyliczaliśmy w pierwszym sposobie.
Swoją drogą, w różnych dostępnych w Internecie implementacjach możesz też znaleźć różne podejścia do sumowania i decydowania, kiedy powinno się mnożyć przez 2. W swojej implementacji, którą zamieszczę poniżej, będę odczytywać liczbę od końca. Mimo że algorytm sugeruje przechodzenie przez liczbę dwukrotnie, ja wykonam wszystko w jednej pętli.
Implementacja
Poniżej możesz zobaczyć implementację algorytmu Luhna (w JavaScript) wykorzystującą oba opisane przed chwilą sposoby (przy generowaniu stosuję pierwszy, przy sprawdzaniu drugi):
// funkcja generująca sumę kontrolną dla numeru
// zakładamy, że numer jest stringiem
function generateChecksum(number) {
// rozbijamy numer na pojedyncze cyfry
// i dokonujemy ich konwersji na typ liczbowy,
// a następnie odwracamy tablicę
const digits = number.split('').map(x => parseInt(x)).reverse();
// zmienna przechowująca sumę
let sum = 0;
// pętla obliczająca sumę
for (let i = 0; i < digits.length; i++) {
// sprawdzamy, czy aktualna cyfra jest na parzystej pozycji
const isEven = (i + 1) % 2 === 0;
if (isEven) {
// w przypadku parzystych po prostu sumujemy
sum += digits[i];
} else {
// w przeciwnym przypadku mnożymy przez 2
const tmp = digits[i] * 2;
// dodajemy odpowiednią liczbę do sumy
if (tmp > 9) {
sum += tmp - 9;
} else {
sum += tmp;
}
}
}
return (10 - (sum % 10)) % 10;
}
// funkcja sprawdzająca poprawność numeru
// zakładamy, że numer jest stringiem
function isValid(number) {
// tablica do obliczania wyniku sumowania dwóch cyfr
const sumArray = [0, 2, 4, 6, 8, 1, 3, 5, 7, 9];
// rozbijamy numer na pojedyncze cyfry
// i dokonujemy ich konwersji na typ liczbowy,
// a następnie odwracamy tablicę
const digits = number.split('').map(x => parseInt(x)).reverse();
// zmienna przechowująca sumę
let sum = 0;
// pętla obliczająca sumę
for (let i = 0; i < digits.length; i++) {
// sprawdzamy, czy aktualna cyfra jest na parzystej pozycji
const isEven = (i + 1) % 2 === 0;
if (isEven) {
// w przypadku parzystych mnożymy przez 2
sum += sumArray[digits[i]];
} else {
// w przeciwnym przypadku dodajemy
sum += digits[i];
}
}
return sum % 10 === 0;
}
Możesz ją przetestować na repl.it.
Inne algorytmy
W tym momencie zasadne byłoby zadanie pytania, czy istnieją inne algorytmy ogólnego zastosowania jak algorytm Luhna? Odpowiedź brzmi: tak. Możemy wymienić przykładowo:
- rozszerzony algorytm Luhna (znany też jako algorytm mod N) — oprócz cyfr obsługuje też litery, które otrzymują wartości od 10 wzwyż
- algorytm Verhoeffa
- algorytm Damma
Jeśli jesteś ciekaw(a), jak one wyglądają oraz jak je zaimplementować, zachęcam do poszukania na własną rękę. Większość z nich można znaleźć dobrze opisane na Wikipedii.
Sumy kontrolne danych cyfrowych
Poznaliśmy temat cyfr kontrolnych, ale teraz możesz się zastanawiać — jak to przełożyć na dowolne dane, które obsługuje komputer? Przecież na samym początku artykułu wspomniałem, że za pomocą tego sposobu sprawdza się chociażby, czy plik pobrany z Internetu dotarł do nas w całości. Zapoznajmy się z podstawowymi podejściami do obliczania sum kontrolnych dla danych binarnych.
Bit parzystości
Najprostsza suma kontrolna stosowana przy danych binarnych to bit parzystości. Jest to bit doklejany na końcu danych, który w zależności od tego, którą definicję stosujemy, mówi, czy w liczbie powinna być parzysta lub nieparzysta liczba jedynek.
Podstawowy sposób obliczania
Jeśli bit parzystości określa, czy liczba jedynek jest parzysta (ang. even parity), wartość 0 oznacza parzystą liczbę jedynek. Możemy to obliczyć, sumując wszystkie cyfry liczby binarnej i obliczając resztę z dzielenia przez 2. Przykład dla liczb 1001 i 1011:
Natomiast aby sprawdzić, czy otrzymaliśmy prawidłową liczbę, sprawdzamy, czy całość ma parzystą liczbę jedynek:
Jeśli bit parzystości określałby nieparzystą liczbę jedynek (ang. odd parity), to wówczas obliczając bit parzystości, powinniśmy dodać dodatkową jedynkę do liczby albo zanegować wynik (czyli 0 zamienić na 1 i na odwrót). Natomiast przy weryfikacji liczby sprawdzamy, czy liczba jedynek jest nieparzysta.
Bez dodawania i modulo
Metoda obliczania bitu parzystości jest stosowana na niskim poziomie, gdzie raczej operujemy bramkami logicznymi, a nie dodawaniem i modulo. Ewentualnie korzystamy z operacji bitowych na poziomie języka programowania. Przedstawię trzy podejścia, jak za pomocą funkcji logicznych i operacji bitowych obliczyć bit parzystości (podejście even parity).
Dzielenie na pół
Pierwsze podejście może nasunąć skojarzenie z sortowaniem przez scalanie, gdzie rekurencyjnie dzielimy kolejne dane na pół. Tutaj robimy coś podobnego, ale wykonując po drodze obliczenia, aby ostatecznie otrzymać jeden bit. Wygląda to następująco:
- Dzielimy liczbę na dwie równe części.
- Obliczamy XOR (alternatywę rozłączną) obu liczb.
- Jeśli wynik w postaci binarnej ma więcej niż jedną cyfrę, wykonujemy algorytm ponownie, tylko na otrzymanym wyniku.
XOR to funkcja logiczna, która zwraca prawdę, gdy oba argumenty są od siebie różne, a fałsz w przeciwnym przypadku. W wielu językach programowania znajdziemy ją pod operatorem ^, zaś w logice jako jeden z następujących symboli: , , , , .
Obliczanie tą metodą mogłoby wyglądać następująco dla liczby (nieparzysta liczba jedynek — oczekujemy 1):
Dzielenie na pary
Alternatywnie, jeśli nie mamy możliwości obliczania XOR dla liczb większych niż jednobitowe (czyli np. gdy korzystamy z bramek logicznych), możemy zamiast dzielić liczbę na dwie równe części, podzielić ją na pary. Następnie obliczamy XOR każdej z par i z wyników tworzymy kolejne pary, które XORujemy, co robimy tak długo, aż otrzymamy jedną cyfrę.
Wyglądałoby to następująco dla tej samej liczby co wcześniej:
Jak poprzednią metodę mogłeś(-aś) skojarzyć sobie z procesem dzielenia w sortowaniu przez scalanie, tak tutaj można powiązać to z operacją scalania. Tylko tyle, że zamiast sortować, to XORujemy.
Przesuwanie bitów
Jeszcze inny sposób polega na wykorzystaniu przesunięć bitowych i funkcji XOR. Wersja ta ma tę zaletę, że jest stosunkowo najprostsza do zaprogramowania.
Algorytm brzmi następująco:
- Stwórzmy zmienną, która będzie przechowywać wyniki kolejnych operacji. Nadajmy jej wartość 0.
- Dopóki liczba jest różna od zera:
- Wykonaj operację XOR na wyniku i liczbie, a następnie przypisz rezultat do zmiennej z wynikiem.
- Przesuń liczbę w prawo o 1 bit.
- Zwróć ostatni bit zmiennej z wynikiem.
Poniżej możesz zobaczyć, w jaki sposób można to zaprogramować w JavaScript:
// funkcja obliczająca bit parzystości
// zakładamy, że liczba jest typu liczbowego
function calculateParityBit(number) {
// zmienna przechowująca rezultat
let result = 0;
// wykonujemy całość tak długo,
// dopóki nie przesuniemy liczby za daleko
while (number !== 0) {
// wykonujemy XOR aktualnego wyniku z liczbą
result ^= number;
// przesuwamy liczbę o 1 bit w prawo
number >>= 1;
}
// wyciągamy ostatni bit zmiennej z wynikiem,
// bo zawiera on wyliczony bit parzystości
return result & 1;
}
Powyższy kod możesz przetestować na repl.it.
Adler-32
Bit parzystości jest bardzo prostym sposobem i sprawdza się np. w transmisji danych. Jednak gdy mamy do czynienia z danymi zapisanymi na dysku, których poprawność chcemy sprawdzić, możemy stosować bardziej rozbudowane algorytmy. Przede wszystkim takie, które obliczą sumę kontrolną dłuższą niż 1 bit, a tym samym lepiej wykrywającą błędy, szczególnie przy większych danych. Przykładem takiego algorytmu jest Adler-32 wykorzystywany m.in. w bibliotece do kompresji danych zlib (używanej np. przy tworzeniu plików .gz).
Algorytm wylicza dwie 16-bitowe sumy kontrolne, które finalnie są łączone w jedną 32-bitową. Pierwsza suma kontrolna (A) to suma wszystkich bajtów liczby (8-bitów danych, traktowane jako liczba) plus 1, natomiast druga suma kontrolna (B) to suma wszystkich kroków potrzebnych do obliczenia pierwszej. Dla obu sum, aby były 16-bitowe, wykonujemy operację modulo 65521, które to jest największą 16-bitową liczbą pierwszą. Ostateczną sumą kontrolną jest złączenie obu wyliczonych sum w jedną (z lewej B, z prawej A).
Matematycznie moglibyśmy zapisać to następująco ( to kolejne bajty liczby):
Natomiast w kodzie (JavaScript) wygląda to następująco:
// funkcja wyliczająca sumę kontrolną algorytmem Adler-32
// zakładamy, że `bytes` jest tablicą liczb w zakresie [0-255]
function adler32(bytes) {
// inicjalizujemy zmienne przechowujące obie sumy kontrolne
let a = 1;
let b = 0;
// iterujemy po kolejnych bajtach
for (const byte of bytes) {
// A zwiększamy o aktualny bajt i liczymy modulo 65521
a = (a + byte) % 65521;
// B zwiększamy o aktualną wartość A i liczymy modulo 65521
b = (b + a) % 65521;
}
// przesuwamy B o 16 bitów i "doczepiamy" A
// "doczepić" możemy za pomocą operacji OR
return b << 16 | a;
}
Możesz go przetestować na repl.it.
Inne algorytmy
Żeby już nie rozwlekać artykułu o kolejne implementacje, opiszę krótko, jakie jeszcze inne algorytmy obliczania sum kontrolnych możemy spotkać:
- Algorytm Fletchera. Zasada obliczania sumy kontrolnej jest bardzo podobna do Adler-32 (podział na dwie sumy, ten sam sposób obliczania), przy czym do operacji modulo zamiast największej liczby pierwszej używamy po prostu największą liczbę, jaką można zapisać na n bitach (czyli ). Stąd algorytm ten jest mniej odporny na kolizje.
- Cykliczny kod nadmiarowy (po ang. Cyclic Redundancy Check, w skrócie CRC). Zdecydowanie najpopularniejszy algorytm, wykorzystywany np. w sieciach telekomunikacyjnych. Polega na ciągłym XORowaniu kolejnych bitów liczby o wskazany przez konkretną implementację algorytmu wielomian CRC. Warto w tym miejscu dodać, że oprócz wykrycia błędów z CRC jesteśmy w stanie też naprawić proste błędy w danych.
- Ciekawostka poboczna: algorytm obliczania bitu parzystości to CRC-1. Spójrz na ostatni sposób obliczania sum kontrolnych, który pokazywałem — XORujemy tam kolejne bity liczby, czyli to, na czym opiera się obliczanie cyklicznych kodów nadmiarowych.
- Algorytmy obliczania sum kontrolnych z Uniksów BSD i System-V. Raczej dziś nieużywane, gdyż sprawują się gorzej od CRC, ale dla zainteresowanych są wciąż dostępne pod poleceniem
sum(które jest częścią GNU Coreutils). - Własny algorytm obliczania sum kontrolnych znajdziemy także dla pakietów sieciowych. Wywodzi się z protokołu IPv4, stąd znajdziemy go pod nazwą IPv4 header checksum (z ang. suma kontrolna nagłówka IPv4), chociaż jest też używany w ICMP i UDP. Jest dość prosty i opiera się na sumowaniu 16-bitowych fragmentów nagłówka pakietu.
Na marginesie dodam, że w niektórych źródłach można znaleźć informację, iż algorytmy z rodziny CRC nie są funkcjami obliczającymi sumę kontrolną. Bierze się to z faktu, że nie odbywa się tutaj operacja sumowania. Jednak rezultat, jaki otrzymujemy, jak najbardziej spełnia wszystkie cechy tego, czym suma kontrolna powinna być. To, co jest natomiast bezsprzeczne, to fakt, że wszystkie te algorytmy należą do funkcji skrótów (haszujących).
Funkcje skrótu
Idealnie się składa, bo w tym momencie chciałem nieco opowiedzieć o funkcjach skrótu, a dokładniej o kryptograficznych funkcjach skrótu. Nie są to sumy kontrolne, aczkolwiek jedno z ich użyć jest takie samo — weryfikacja poprawności danych, w szczególności całych plików ściągniętych z Internetu. Przy poważniejszych źródłach do ściągania plików możemy znaleźć pliki z zapisanymi sumami kontrolnymi do weryfikacji, czy poprawnie ściągnęliśmy dane. Są one zwykle wyliczane algorytmami MD5, SHA-1 lub SHA-256.


Oryginał znajduje się tutaj: http://releases.ubuntu.com/22.10/, plik SHA256SUMS

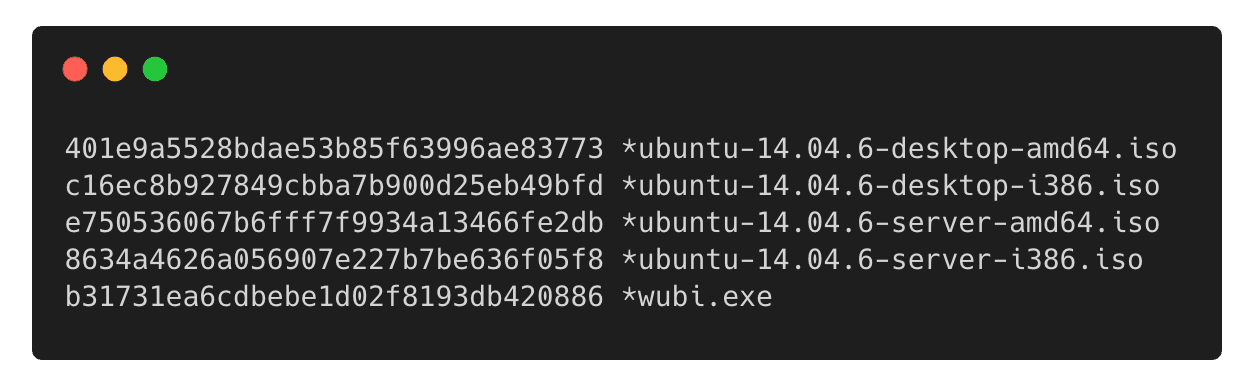
Oryginał znajduje się tutaj: http://releases.ubuntu.com/14.04.6/, plik MD5SUMS
Dobrze, ale o co tutaj chodzi? Celem kryptograficznych funkcji skrótu jest (w skrócie mówiąc) wygenerowanie ciągu znaków bazującego na zadanych danych wejściowych (dla uproszczenia w kontekście tego artykułu nazwijmy go sumą kontrolną, chociaż nie do końca jest to prawda). Niezależnie od rozmiaru danych wejściowych (czy to będzie plik mający 1 bajt, czy 1 gigabajt) wynik funkcji skrótu powinien być zawsze tej samej długości. Do tego nawet niewielkie zmiany w danych powinny wygenerować całkowicie inną sumę kontrolną, a podatność na wygenerowanie kolizji, w szczególności celowych, powinna być jak najmniejsza. Nie będziemy wchodzić w szczegóły algorytmów, bo to temat bardziej rozbudowany i zdecydowanie poza zakresem tego artykułu.
Jeśli chcesz przetestować, jakie wyniki dają wspomniane tutaj funkcje skrótu, to posiadając Linuksa lub macOS (z wgranymi GNU Coreutils), możesz użyć poleceń: md5sum, sha1sum i sha256sum. Służą one zarówno do wygenerowania sum kontrolnych, jak i ich weryfikacji. Poniżej możesz zobaczyć przykład ich użycia. Najpierw wygenerowałem plik z treścią Test i policzyłem jego sumy kontrolne. Następnie utworzyłem kolejny plik z treścią Tfst (różnica 2 bitów) i wykonałem te same polecenia. Sam(a) zobacz, jak tak niewielka zmiana drastycznie zmieniła rezultaty algorytmów.

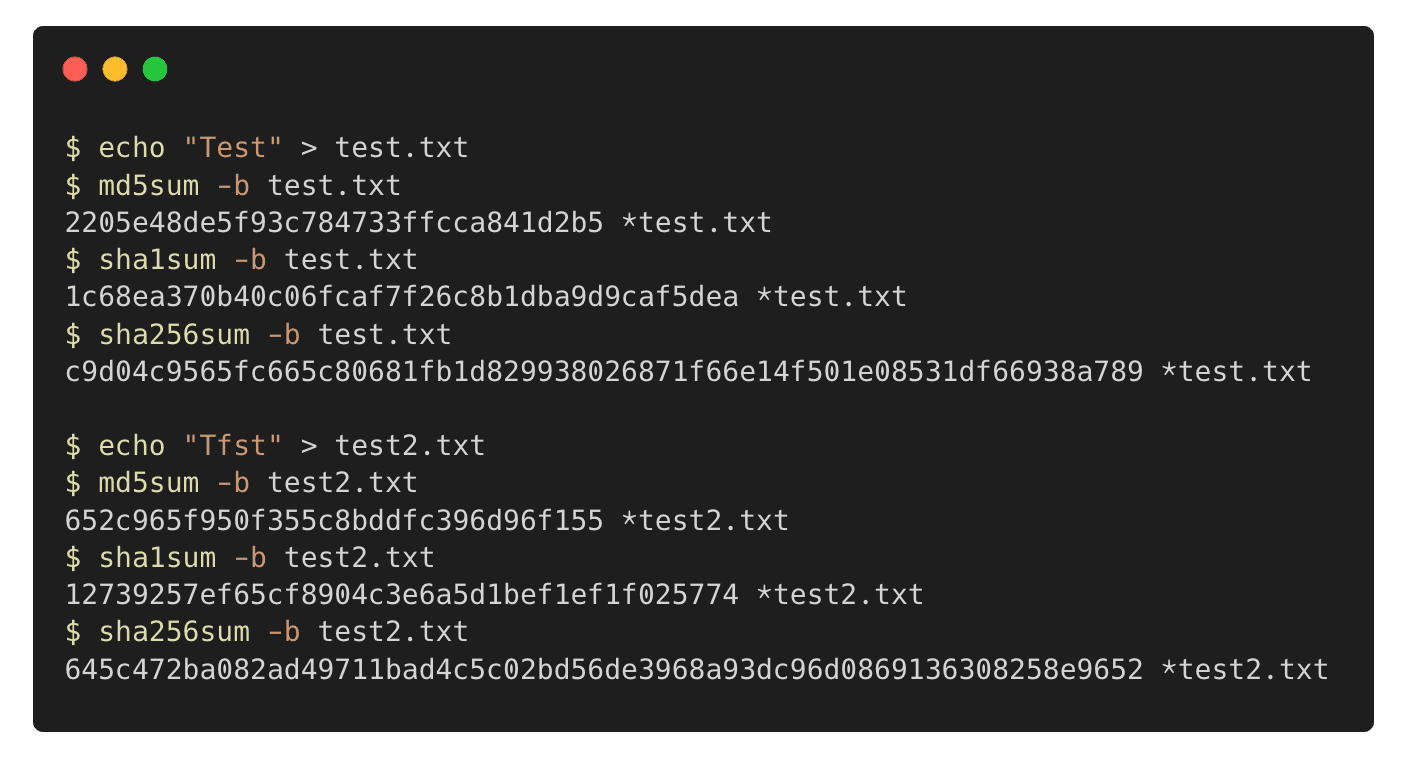
Jak możesz zauważyć na dwóch pierwszych zrzutach ekranu, czy też wchodząc na podlinkowane przy nich strony, o ile Ubuntu 14.04 (wydane w 2014 r.) miało sumy kontrolne wygenerowane przez wszystkie trzy wspomniane przeze mnie algorytmy, tak Ubuntu 22.10 (wydane w 2022 r.) już tylko przez SHA-256. Jest tak dlatego, że zarówno w przypadku SHA-1, jak i MD5 udowodniono, że stosunkowo prosto jest wygenerować celowe, złośliwe kolizje. W przypadku MD5 możesz więcej na ten temat dowiedzieć się tutaj: https://www.mscs.dal.ca/~selinger/md5collision/. Tym samym dziś w użyciu jest przede wszystkim SHA-256.
Podsumowanie
Sumy kontrolne to ciekawe i przydatne zagadnienie. W wielu przypadkach, stosując proste mechanizmy matematyczne, pozwalają nam sprawdzić, czy nie doszło do uszkodzenia danych. Nie zabezpieczają przed celowymi, złośliwymi modyfikacjami (z wyjątkiem SHA-256, które nie do końca jest funkcją sumy kontrolnej), ale wykryją np. omyłkowe złe przepisanie numeru PESEL.
Literatura
- Checksum, https://en.wikipedia.org/w/index.php?title=Checksum&oldid=1138389435 (ostatni dostęp lut. 15, 2023).
- Czym jest numer PESEL, https://www.gov.pl/web/gov/czym-jest-numer-pesel (ostatni dostęp lut. 15, 2023).
- Numer identyfikacji podatkowej, https://pl.wikipedia.org/w/index.php?title=Numer_identyfikacji_podatkowej&oldid=68929461 (ostatni dostęp lut. 15, 2023).
- ECE4253 Secrets of the ISBN, https://www.ece.unb.ca/tervo/ece4253/isbn.shtml (ostatni dostęp lut. 15, 2023).
- ISBN, https://en.wikipedia.org/w/index.php?title=ISBN&oldid=1136764742 (ostatni dostęp lut. 15, 2023).
- Patent US2950048A, Luhn, Hans P., "Computer for verifying numbers", opublikowany 1960-08-23.
- Luhn test of credit card numbers, https://rosettacode.org/w/index.php?title=Luhn_test_of_credit_card_numbers&oldid=336954 (ostatni dostęp lut. 15, 2023).
- Parity bit, https://en.wikipedia.org/w/index.php?title=Parity_bit&oldid=1126848851 (ostatni dostęp lut. 15, 2023).
- Deutsch, P. and J-L. Gailly, "ZLIB Compressed Data Format Specification version 3.3", RFC 1950, DOI 10.17487/RFC1950, maj 1996.
- Fletcher, J. (1982). An Arithmetic Checksum for Serial Transmissions. IEEE Transactions on Communications, 30(1), 247–252. doi:10.1109/tcom.1982.1095369
- Cyclic redundancy check, https://en.wikipedia.org/w/index.php?title=Cyclic_redundancy_check&oldid=1139446396 (ostatni dostęp lut. 15, 2023).
- sum invocation (GNU Coreutils 9.1), https://www.gnu.org/software/coreutils/manual/html_node/sum-invocation.html (ostatni dostęp lut. 15, 2023).
- Internet checksum, https://en.wikipedia.org/w/index.php?title=Internet_checksum&oldid=1130518342 (ostatni dostęp lut. 15, 2023).
- Cryptographic hash function, https://en.wikipedia.org/w/index.php?title=Cryptographic_hash_function&oldid=1139428495 (ostatni dostęp lut. 15, 2023).
- Selinger P., MD5 Collision Demo, 11 paź 2011 https://www.mscs.dal.ca/~selinger/md5collision/ (ostatni dostęp lut. 15, 2023).



Koniecznie polub świstak.codes na Facebooku, obserwuj na Instagramie, LinkedIn lub zasubskrybuj mój kanał RSS!
Możesz też wesprzeć moją działalność klikając link poniżej:
