


Sortowanie, cz. 2 — sortowanie bąbelkowe
W poprzedniej, pierwszej części serii o sortowaniu opisałem teoretyczną część tego zagadnienia. Najwyższy czas przejść do praktyki. Nauczmy się najprostszego z algorytmów sortowania opartego o zamianę elementów — sortowania bąbelkowego, znanego też pod angielską nazwą bubble sort lub jako sortowanie przez zamianę. Jednak to nie wszystko. Będziemy go także krok po kroku optymalizować na tyle, na ile jest to w jego przypadku możliwe.
Uwaga wstępna
Mimo że artykuł opisuje konkretny algorytm, pomijam tutaj implementacje w konkretnym języku programowania. Jednak na potrzeby artykułu powstało trochę kodu do wizualizacji oraz badań. Jeżeli jesteś ciekaw, znajdziesz go w repozytorium na GitHubie: https://github.com/swistak-codes/sorting-algorithms. Kod został napisany w JavaScript, ale jest bogato opatrzony w komentarze w języku polskim, abyś mógł lepiej zrozumieć, co się tam dzieje. Warto też dodać, że szczególnie w przypadku wizualizacji, implementacje te zawierają wiele nadmiarowych kroków (na potrzeby prezentacji krok po kroku i animacji) i nie powinny być stosowane w praktyce.
Czy kolekcja jest posortowana?
Na końcu poprzedniego artykułu podałem Ci zadanie — jak sortować, mając podane typowe ograniczenia, z którymi borykają się programiści. W tym momencie możesz skonfrontować część swoich pomysłów z praktyką.
Zacznijmy od początku. Mamy tablicę dowolnych elementów. Dla naszego przykładu załóżmy, że te elementy to liczby. Co musimy zrobić, aby przekonać się, czy jest posortowana, czy nie? Przejść po kolei po elementach i porównywać dwa sąsiadujące ze sobą. Dwa elementy są w dobrej kolejności? To przechodzimy i porównujemy ze sobą następne dwa. Jeżeli doszliśmy tak do końca tablicy, możemy być zadowoleni — jest posortowana. Jednak jeżeli jakaś para elementów nie jest w dobrej kolejności, możemy przerwać — tablica nie jest posortowana. Zobaczmy to na poniższym schemacie:

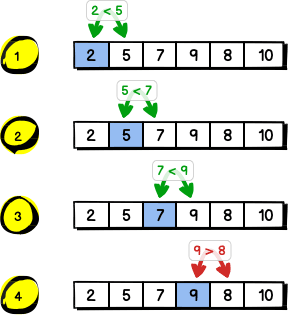
Zapamiętajmy przy okazji, że aby sprawdzić posortowanie tablicy, musieliśmy w najgorszym wypadku (najgorszym, ale najlepszym, bo wtedy jest posortowana) zrobić porównań o jedno mniej niż liczba elementów (czyli ). Informacja ta przyda się nam na później.
Jednakże jest to tylko sposób, aby sprawdzić, czy tablica jest posortowana. Jak możemy z tego przejść do właściwego sortowania?
Zamiana elementów
Skoro przechodzimy po całej tablicy i natrafiamy na elementy w złej kolejności, po prostu zamieńmy je ze sobą miejscami. Oczywiście to nam nie posortuje tablicy — musimy przejść przez całą tablicę jeszcze raz i ponownie zamieniać elementy, gdy jest taka potrzeba. I wciąż tablica jest nieposortowana. W takim razie ile razy musimy tak przechodzić? Otóż tyle razy, ile mamy elementów — w ten sposób możemy być pewni, że każdy trafi na swoje miejsce. Tak oto wynaleźliśmy na nowo sortowanie bąbelkowe*.
Dokładnie taką implementację, jak opisałem wyżej, możesz posprawdzać w poniższej mini aplikacji. Korzystając z kontrolek u góry, wygeneruj tablicę z danymi, po czym zacznij sortowanie. Możesz przechodzić krok po kroku, zobaczyć animację lub od razu przeskoczyć do ostatecznie posortowanej wersji. Na wykresie reprezentującym elementy tablicy oznaczony jest na zielono aktualnie rozpatrywany element w iteracji, a na żółto element, do którego przyrównujemy. Pokombinuj z różnymi układami i obserwuj statystyki:
* nie do końca jest to sortowanie bąbelkowe, które możesz znać z podręczników, ale o tym później
Wydajność
Jak pamiętasz z poprzedniego artykułu, wspomniałem, że sortowanie bąbelkowe jest mało wydajne. I w zasadzie możemy to tutaj zaobserwować. Jeżeli ustawiłeś dużą liczbę elementów, np. 100, mogłeś naprawdę długo czekać, aż animacja skończy się odtwarzać. Dlaczego tak jest? Spójrzmy na statystyki, ile porównań wykonujemy.
Jak pamiętamy, przechodząc raz przez tablicę, wykonujemy porównań. Tutaj przez tablicę przechodzimy n razy, co oznacza, że porównań wykonujemy . Przełóżmy to na konkretne liczby:
- Dla 5 elementów: porównań
- Dla 15 elementów: porównań
- Dla 50 elementów: porównań
- Dla 100 elementów: porównań
- Dla 1000 elementów: porównań!
Powiedzmy sobie szczerze, jest to zbyt dużo. Dla tysiąca elementów musimy wykonać niemal milion porównań. A jak duże zbiory danych sortujemy? Przykładowo, na popularnym portalu aukcyjnym wszedłem w kategorię z akcesoriami fotograficznymi, która zawiera ponad 300 tysięcy produktów, a ich posortowanie po dowolnym kryterium zajmuje chwilę. Więc jak to jest możliwe?
Oczywiście odpowiedź jest bardzo prosta — nikt w prawdziwych zastosowaniach nie używa sortowania bąbelkowego. Ale nawet w przypadku tego algorytmu możemy pozwolić sobie na optymalizacje, które zmniejszą liczbę wymaganych porównań.
Porównujmy mniej elementów
Tylko jak w prosty sposób porównywać mniej elementów? Zobaczmy, co się dzieje, przechodząc algorytm krok po kroku. W wyniku zamiany elementów, już po pierwszej iteracji zawsze mamy jeden element na właściwym miejscu — dokładniej to ostatni element jest tam, gdzie powinien być. Co się dzieje w kolejnej? Przedostatni jest na właściwym miejscu. Własność ta utrzymuje się aż do samego końca. W takim razie oznacza to, że nie musimy za każdym razem iterować całej tablicy. Z każdym kolejnym przejściem algorytmu zmniejszajmy zakres porównań o jeden.
W taki oto sposób otrzymaliśmy właściwy algorytm sortowania bąbelkowego, czyli taki, jaki znajdziemy w dowolnym podręczniku do informatyki. Możesz pobawić się tym algorytmem, wykorzystując poniższą aplikację. Sposób działania identyczny jak poprzednio:
Jak możemy zauważyć, liczba porównań zmalała i to dość znacznie, bo niemal o połowę. Jednak wciąż mamy pewne pole do popisu.
Nie przechodźmy do końca
W przypadku danych ułożonych w losowy sposób, a nawet jeszcze bardziej przy danych już uprzednio posortowanych, można zwrócić uwagę na jedną bolączkę algorytmu — kontynuujemy sortowanie, mimo że dane są już posortowane. Naprawmy to. A jak to zrobić? Najprościej... sprawdzając, czy kolekcja jest posortowana (czyli wracamy do początku artykułu), i jeżeli jest, to przerywamy algorytm. Można to zresztą połączyć już z aktualnym mechanizmem działania — zapamiętujmy co iterację, czy dokonaliśmy zamianę, czy też nie. Jeśli nie, oznacza to, że kolekcja jest posortowana i nie musimy już dalej wykonywać algorytmu.
Chcesz sprawdzić, jak to działa? Zapraszam poniżej:
Sytuacja znacznie nam się poprawiła. Byliśmy w stanie, w typowym przypadku (losowo rozmieszczone dane), jeszcze bardziej zmniejszyć liczbę porównań. Wciąż jest ich dużo, nadal ich liczba jest niebezpiecznie bliska do , jednak algorytm już teraz działa zauważalnie szybciej w porównaniu do pierwszej wersji.
Zatem możesz teraz zadać pytanie — czy możemy zrobić coś jeszcze, aby poprawić wydajność? Otóż tak.
Problem „żółwi i zajęcy”
Wykonując algorytm sortowania bąbelkowego zaobserwuj tempo przesuwania się elementów na właściwe pozycje. Końcowe elementy bardzo szybko znajdują swoje właściwe pozycje (zresztą na tej podstawie zrobiliśmy pierwszą optymalizację), jednak początkowe bardzo powoli przechodzą na swoje miejsce. Problem ten szczególnie można zauważyć, sortując kolekcję posortowaną odwrotnie. W literaturze problem ten nazwany jest problemem żółwi i zajęcy.
Sortowanie koktajlowe
Czy jesteśmy w stanie to rozwiązać? Tak, nieco modyfikując algorytm. Tym razem wprowadzimy nieco mocniejszą zmianę — przechodźmy tablicę na przemian. Raz idźmy od początku do końca (czyli normalnie), a następnym razem od końca do początku. Oczywiście wciąż pamiętajmy o skracaniu przedziałów (tym razem z obu stron!) i przerywaniu, gdy tablica jest posortowana. Tak oto otrzymaliśmy sortowanie bąbelkowe, działające jednocześnie z obu stron. Znane jest ono pod nazwą sortowanie koktajlowe lub sortowanie mieszane (angielskie nazwy: shaker sort, cocktail sort, cocktail shaker sort).
Tutaj możesz przetestować, jak działa ten algorytm:
Można zauważyć, że udało nam się nieco zmniejszyć liczbę porównań, ale wciąż jest to dalekie od ideału. Niestety, niewiele już możemy tutaj zrobić. Co prawda są jeszcze sposoby optymalizacji polegające na mocniejszym zmniejszaniu przedziałów, jednak pominę ich opis.
Sortowanie grzebieniowe
Problem żółwi i zajęcy możemy rozwiązać jeszcze w inny sposób. Jest mniej oczywisty, trudniejszy, ale dający lepsze rezultaty. Ta odmiana sortowania bąbelkowego nazywa się sortowaniem grzebieniowym (comb sort) i została opracowana w 1980 przez Włodzimierza Dobosiewicza (stąd czasem spotykana jest pod nazwą Dobosiewicz sort).
Idea rozwiązania problemu żółwi i zajęcy jest tutaj taka, że aby rozmieszczać elementy na swoje miejsca w miarę równomiernie, nie porównujemy elementów znajdujących się obok siebie, lecz elementy trochę bardziej od siebie rozstawione. Następnie co iterację ten rozstaw zmniejszamy, aż w ostatniej schodzimy do typowego sortowania bąbelkowego. Co iterację zmniejszamy rozstawienie, dzieląc poprzednie (a na początku rozmiar tablicy) przez współczynnik 1,3. Jest to niewielka zmiana, jednak potrafi znacząco zmniejszyć liczbę porównań.
Tutaj możesz sprawdzić działanie sortowania grzebieniowego:
Wydajność i właściwości sortowania bąbelkowego
Sortowanie bąbelkowe to zdecydowanie najprostszy z dostępnych algorytmów sortowania, ale jednocześnie mało wydajny. Liczba porównań w nim jest zazwyczaj bliska liczbie elementów tablicy podniesionej do kwadratu, co daje nam wydajność . Jest to niestety słaby rezultat, ponieważ oznacza zbyt szybki wzrost złożoności obliczeniowej, co przekłada się również na czas wykonywania programu. Mimo wprowadzania kolejnych optymalizacji nie jesteśmy w stanie w znaczący sposób zmniejszyć tej liczby. Najlepiej wygląda tu ostatnia przytoczona, czyli sortowanie grzebieniowe, jednak wciąż wymaga dużej liczby porównań.
Z tego wszystkiego, co tutaj napisałem, można dość łatwo wywnioskować, że sortowanie bąbelkowe nie ma żadnych zastosowań poza edukacyjnymi. Właśnie ta jego prostota pozwala nam na bardzo przyjemne tłumaczenie algorytmiki stojącej za sortowaniem.
Jednak w poprzednim artykule także mówiliśmy o zagadnieniu stabilności algorytmu. W ramach tego artykułu nie przeprowadzamy badań, ale na podstawie fachowej literatury mogę podać następujące informacje:
- Sortowanie bąbelkowe jest algorytmem stabilnym.
- Sortowanie koktajlowe również jest stabilne.
- Sortowanie grzebieniowe jest algorytmem niestabilnym.
Podsumowanie
Sortowanie bąbelkowe to najprostszy dostępny algorytm sortowania. Traktujmy go jednak wyłącznie jako ciekawostkę, ponieważ z racji swojej wydajności nie ma on praktycznych zastosowań. Dlatego też seria artykułów nie zakończy się na tym. W przyszłości opiszę inne algorytmy sortowania, w tym te bardziej wydajne.
Literatura
- Knuth D. E., „Sortowanie przez zamienianie” w Sztuka programowania Tom 3 Sortowanie i wyszukiwanie. Warszawa: Wydawnictwa Naukowo-Techniczne, 2002, s. 110-145
- Wirth N., „Sortowanie przez prostą zamianę” w Algorytmy + struktury danych = programy. Warszawa: Wydawnictwa Naukowo-Techniczne, 2002, s. 82–86
- Dobosiewicz W., An Efficient Variation of Bubble Sort. „Information Processing Letters”. 11(1): 5-6, 1980.
- Lacey S., Box R.., „A fast, easy sort”. BYTE 16, 4 (kwiecień 1991), 315–320.



Koniecznie polub świstak.codes na Facebooku, obserwuj na Instagramie, LinkedIn lub zasubskrybuj mój kanał RSS!
Możesz też wesprzeć moją działalność klikając link poniżej:
